构建高效数据处理服务 项目规划与实施指南
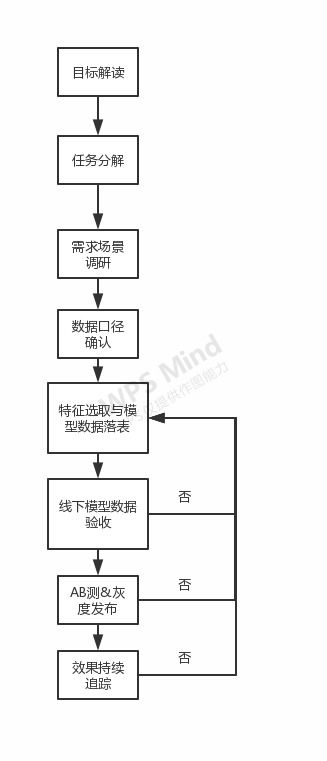
随着企业数据规模的持续膨胀,数据处理服务已成为现代业务运营的核心支撑。一个精心规划的数据处理项目,不仅能确保数据流的顺畅与准确,更能为企业决策提供强有力的洞察。本文将系统性地阐述如何规划与实施一个稳健、高效的数据处理服务项目。
第一阶段:需求分析与目标设定
项目成功的基石在于清晰的需求定义。需要与业务部门深入沟通,明确数据处理的范畴:是实时流处理还是批量处理?数据来源包括哪些(如数据库、日志文件、IoT设备)?处理后的数据将服务于哪些具体场景(如报表生成、用户画像、风险预警)?需设定可衡量的项目目标,例如将数据处理延迟降低50%,或实现99.9%的数据准确率。明确的范围与目标是后续所有技术选型和架构设计的总纲。
第二阶段:技术架构与工具选型
基于需求,设计数据处理的技术架构。核心通常包括数据采集、存储、计算与输出四大模块。
1. 采集层:根据数据源特性,可选择Apache Kafka、Flink CDC进行实时采集,或使用Sqoop、DataX进行批量同步。
2. 存储层:需考虑数据湖与数据仓库的搭配。原始数据可存入HDFS、S3等构建数据湖;处理后的结构化数据则可导入ClickHouse、Snowflake等数据仓库,以供高效分析。
3. 计算层:这是核心处理引擎。对于批量ETL任务,Apache Spark以其强大的内存计算能力成为主流选择;对于实时处理,Apache Flink提供了高吞吐、低延迟的流处理能力。
4. 调度与运维:采用Apache Airflow或DolphinScheduler对数据处理流水线进行可视化编排、调度与监控,确保任务依赖关系清晰、执行可靠。
选型时务必权衡团队技术栈、社区生态、成本与性能,避免过度追求新技术而增加复杂度。
第三阶段:详细设计与开发实施
本阶段将架构蓝图转化为可执行代码。关键任务包括:
- 数据流水线设计:定义每个处理步骤的输入、输出、转换逻辑与容错机制。例如,设计数据清洗规则以处理缺失值与异常值。
- 数据模型与Schema管理:设计目标数据模型,并建立严格的Schema演进协议,确保上下游兼容。
- 开发与测试:遵循模块化开发原则,实现各处理单元。必须建立完备的测试体系,包括单元测试(验证单个处理逻辑)、集成测试(验证流水线衔接)和数据质量测试(验证产出数据的准确性、完整性与一致性)。
第四阶段:部署、监控与迭代优化
将开发完成的服务部署到生产环境(如Kubernetes集群),并配置完备的监控告警体系。监控应覆盖:
- 资源层面:CPU、内存、磁盘IO使用率。
- 业务层面:数据处理延迟、吞吐量、任务成功率、数据质量指标(如重复记录数)。
- 告警机制:当关键指标异常时,能及时通知运维人员。
项目上线并非终点。需建立常态化的性能评估与优化机制,例如通过数据倾斜优化、缓存策略、计算资源弹性伸缩等手段,持续提升服务效率与成本效益。
****
规划一个数据处理服务项目是一项系统工程,贯穿业务、技术与运维。成功的核心在于以清晰的业务目标为导向,选择稳健且匹配的技术栈,并在全周期贯彻严格的数据质量管控与持续的效能优化。通过上述四个阶段的周密规划与执行,企业能够构建一个灵活、可靠的数据处理中枢,为数据驱动型决策奠定坚实基础。
如若转载,请注明出处:http://www.fpcnt.com/product/2.html
更新时间:2026-03-15 21:45:17